
Теория
Программа социологического исследования состоит из разделов: методологического и процедурного. Методологический раздел предполагает постановку цели, задач, определение проблемы и объекта исследования, интерпретацию понятий, выдвижение гипотез. На процедурном этапе составляется план исследования, формируется набросок процедур сбора и анализа данных, обосновывается система выборки.
Построить систему выборки означает определить тип выборки, отобрать и рассчитать единицы исследования. При построении выборки необходимо понимать основные термины калькулятора: объект исследования, генеральная и выборочная совокупность, а также единица исследования.
Объект исследования и генеральная совокупность- это не одно и то же. Под объектом исследования подразумевается понятие, на основании которого происходит отбор и идентификация единиц исследования. Генеральная совокупность по факту является совокупностью единиц исследования, т.е. численным выражением объекта исследования.
«Москвичи» -это объект исследования. Понятие «москвичи» позволяет отбирать из всех россиян только тех, кто проживает в Москве. Генеральная совокупность- это число жителей г. Москва. Выборочная совокупность – это часть генеральной совокупности, количество которой зависит от типа выборки, целей исследования. Каждый москвич- это единица исследования.
Как отобрать из всех «москвичей» тех, кто будет входить в выборочную совокупность? В социологии выделяют два вида способов отбора единиц исследования: случайные и неслучайные.
Случайные способы — это способы, которые предоставляют равные ненулевые возможности каждой единице исследования попасть в выборку.
К случайным методам отбора единиц исследования Н.Н.Чурилов относит:
- Стратификационный отбор, т.е. разделение выборки на однородные группы и последовательный отбор единиц исследования уже из этих групп. Это жители одного микрорайона, представители молодежи;
- Случайный отбор — это отбор, при котором единицы исследования выстраиваются в порядок, список и отбираются, чаще всего, с помощью таблицы случайных чисел;
- Гнездовой отбор — это отбор, который в качестве единицы исследования рассматривает не одного человека, а зачастую группу. При этом учитывается мнение не всех членов «гнезда», а только одного. Семья, домохозяйство, субкультура- примеры гнездовой выборки;
- Систематический отбор схож со случайным, но основывается не на вероятностных процедурах, а на алфавитных списках, данных из баз, книге с номерами и адресами и т.д. В этом виде отбора имеет место шаг отбора, т.е. установленный интервал, через который отбираются респонденты. К примеру, опрашивается каждый третий пациент поликлиники (шаг=3).
Неслучайные способы не основываются на случайном отборе. Исследователь произвольно определяет структуру и состав выборки. К ним относятся:
- Квотный отбор- отбор, при котором каждое структурное подразделение генеральной совокупности имеет отражение в выборке с соответствующим процентом единиц исследования;
- Целевой отбор — отбор, при котором в выборку попадают представители только целевой группы.
- Метод «снежного кома»- способ отбора единиц исследования, подразумевающий, что человек, который участвовал в исследовании, привлечет новых респондентов.
По принципу построения выборки социологические исследования делят на сплошные и выборочные. Сплошные исследования характеризуются тем, что респондентами становится вся генеральная совокупность. Сплошная выборка применяется в том случае, если необходимо изучить мнение всех, без исключений. Перепись населения — яркий пример сплошного исследования.
Выборочные исследования отличаются тем, что они ограничивают круг респондентов, т.е. не вся совокупность единиц исследования входит в выборку. В таком случае необходимо рассчитать размер выборки.
Размер выборки зависит от двух факторов:
- Степени однородности генеральной совокупности. Наблюдается обратная зависимость: чем выше степень однородности, тем меньше может быть объем выборки и наоборот.
- Количества ключевых параметров, на основании которых строится выборка. Параметры являются фильтрами отбора единиц исследования в выборку.
Размер выборки рассчитывается по формуле, в которой необходимо знать генеральную совокупность, определить желаемую и/или необходимую доверительную вероятность и доверительный интервал (погрешность). Формула, по которой производится расчет, также имеет показатель Z, значение которого зависит от доверительного уровня.
Доверительный интервал (погрешность)- это предельные значения, в рамках которых с установленной доверительной вероятностью попадет статистическая величина.
Доверительная вероятность есть показатель статистической вероятности того, что случайно выбранный ответ попадет в доверительный интервал. Высокой доверительной вероятностью считается 95% и 99%, средней- 85% и 80%. Чем выше доверительная вероятность, тем большее число человек необходимо включить в выборку.
Доверительная вероятность в 95% и соответственно +/- 5% погрешности в опросе москвичей будут означать, что случайно отобранный ответ в 95% случаев по статистике попадет в доверительный интервал.
Калькулятор также предлагает варианты расчета необходимого объема выборки и под другие доверительные интервалы.
Требованием к построению выборки является репрезентативность. Репрезентативность для исследования означает, что состав выборки по ряду параметров соответствует пропорциям генеральной совокупности.
Исследователь выделяет параметры, которые имеют ключевое значение. Им должна соответствовать выборочная совокупность. Чаще всего к ним относят: пол, возраст, профессию/должность, семейное положение, уровень дохода, образование и т.д.
Для того чтобы определить, насколько репрезентативна выборка, рассчитывается показатель «ошибка выборки». Социологи считают, что высокая надежность выборочного отбора допускает ошибку выборки в 3%, стандартная — в среднем 3-10%, приближенная варьируется от 10-20%, ориентировочная- в среднем 20-40%, а прикидочная оценивается в 40% и более.
Калькулятор производит расчет погрешности, принимая условие, что генеральная совокупность больше, чем объем выборки. Однако, формулы расчета при этом условии и обратном ему различны.
Ошибки выборки могут быть случайными и систематическими.
Систематические отклонения возникают, если при разработке программы исследования была допущена концептуальная ошибка. Неправильно выбранный параметр либо игнорирование значимых параметров, неточность расчета выборочной совокупности и как следствие смещение выборки — примеры часто встречающихся систематических ошибок.
Распространенными систематическими ошибками считаются:
- Давление доступных объектов. Данная ошибка проявляется в том случае, если выводы, полученные в результате исследования только доступной части выборки, обобщаются и проектируются на всю выборочную совокупность.
- Иллюзия постоянства. Ошибка иллюзии постоянства заключается в том, что при проведении исследования пренебрегается та категория, которая не имеет четкого мнения. Но мнение может сформироваться, поменяться. В этом случае исследователь упускает ценную информацию.
- Недостаточный учет аномальных и труднодоступных единиц исследования. Речь идет о том, что в случае возникновения трудностей с налаживанием контакта, получением доступа к некоторым категориям населения, исследователь может ими пренебречь. Если учет аномальных и труднодоступных единиц исследования не отражен в концепции исследования, в задачах, гипотезах, то его можно опустить без риска снижения качества данных.
- Отказ от ответа. Отказ от ответа плох тем, что человек уже стал респондентом, его ответ фиксируется, но он не является информативным. А также значительно изменяют усредненные показатели, выводы.
Случайные ошибки бывают двух видов.
Первый вид включает случайные ошибки, которые появляются на этапах наблюдения и сбора информации. Это ошибки процедурные. Причинами допущения такого рода ошибок может быть неквалифицированный интервьюер/ анкетер, а также неполный охват выборки.
Второй вид случайных ошибок выражается в отклонении характеристик выборки от характеристик генеральной совокупности. Случайные ошибки можно исправить, организовав дополнительный сбор информации.
Построение и обоснование выборки- важный процедурный этап. От того, насколько грамотно исследователь отберет респондентов, зависит успешность исследования, точность и надежность, релевантность данных. Важно помнить, что выборка строится, исходя из концепта исследования, поставленных целей и задач, выдвинутых гипотез. Также не менее важны сущностные характеристики объекта исследования, учет которых требует корректировки выборки. Единой формулы для грамотного построения выборки нет. Необходимо разрабатывать исследование, в частности, выборку поэтапно. В этом случае есть вероятность минимизировать ошибки. А выполнить рутинную работу вам всегда поможет калькулятор.
Как рассчитать выборку
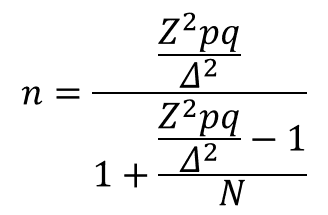
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели соков и нектаров, постоянно проживающие в Москве и Московской области). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален. В данном калькуляторе значения p и q по умолчанию равны 0,5.
Δ– предельная ошибка выборки (для доли признака, доверительный интервал («погрешность» ± %)), приемлемая для исследователя. Считается, что для принятия бизнес-решений ошибка выборки не должна превышать 4%.
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании.
Как рассчитать доверительный интервал (погрешность)
Генеральная совокупность значительно больше выборки
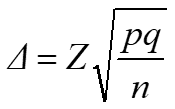
Генеральная совокупность сопоставима с объемом выборки
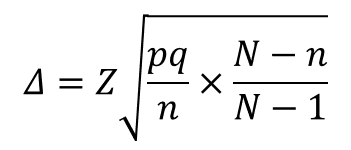
n – объем выборки,
N – объем генеральной совокупности,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня (так же называют Z фактор),
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует, (значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования)
∆ – предельная ошибка выборки, ± %.
Таблица Z фактор
| Доверительная вероятность, % | Z фактор |
|---|---|
| 85 | 1.28 |
| 90 | 1.645 |
| 95 | 1.96 |
| 97 | 2.17 |
| 99 | 2.58 |
| 99.7 | 3 |